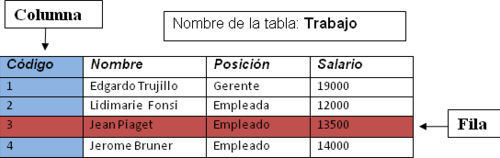
La primera forma normal (1FN o forma mínima) es una forma normal usada en normalización de bases de datos. Una tabla de base de datos relacional que se adhiere a la 1FN es una que satisface cierto conjunto mínimo de criterios. Estos criterios se refieren básicamente a asegurarse que la tabla es una representación fiel de una relación y está libre de "grupos repetitivos".
Sin embargo, el concepto de "grupo repetitivo", es entendido de diversas maneras por diferentes teóricos. Como consecuencia, no hay un acuerdo universal en cuanto a qué características descalificarían a una tabla de estar en 1FN. Muy notablemente, la 1FN, tal y como es definida por algunos autores excluye "atributos relación-valor" (tablas dentro de tablas) siguiendo el precedente establecido por (E.F. Codd) (algunos de esos autores son: Ramez Elmasri y Shamkant B. Navathe). Por otro lado, según lo definido por otros autores, la 1FN sí los permite (por ejemplo como la define Chris Date).
Las tablas 1FN como representaciones de relaciones
Según la definición de Date de la 1FN, una tabla está en 1FN si y solo si es "isomorfa a alguna relación", lo que significa, específicamente, que satisface las siguientes cinco condiciones:
- 1. No hay orden de arriba-a-abajo en las filas.
- 2. No hay orden de izquierda-a-derecha en las columnas.
- 3. No hay filas duplicadas.
- 4. Cada intersección de fila-y-columna contiene exactamente un valor del dominio aplicable (y nada más).
- 5. Todas las columnas son regulares [es decir, las filas no tienen componentes como IDs de fila, IDs de objeto, o timestamps ocultos].
- —Chris Date, "What First Normal Form Really Means", pp. 127-8
La violación de cualesquiera de estas condiciones significaría que la tabla no es estrictamente relacional, y por lo tanto no está en 1FN. Algunos ejemplos de tablas (o de vistas) que no satisfacen esta definición de primera forma normal son:
- Una tabla que carece de una clave primaria. Esta tabla podría acomodar filas duplicadas, en violación de la condición 3.
- Una vista cuya definición exige que los resultados sean retornados en un orden particular, de modo que el orden de la fila sea un aspecto intrínseco y significativo de la vista. Esto viola la condición 1. Las tuplas en relaciones verdaderas no están ordenadas una con respecto de la otra.
- Una tabla con por lo menos un atributo que pueda ser nulo. Un atributo que pueda ser nulo estaría en violación de la condición 4, que requiere a cada campo contener exactamente un valor de su dominio de columna. Sin embargo, debe observarse que este aspecto de la condición 4 es controvertido. Muchos autores consideran que una tabla está en 1FN si ninguna clave candidata puede contener valores nulos, pero se aceptan éstos para atributos (campos) que no sean clave, según el modelo original de Codd sobre el modelo relacional, el cual hizo disposición explícita para los nulos.